From GPT Wrapper to Production Agent — What Most AI Products Get Wrong
The AI startup graveyard is full of products that worked in the demo and broke in production. Here's what they got wrong, and what a real agent architecture looks like.

The demo went great. CEO loved it. Investors nodded approvingly. The AI answered three questions about the company's sales data, got them all right, and everyone clapped.
Six weeks later, the product was in the trash.
Not because it stopped working. It had never really worked. The demo was a curated path through a minefield. Three questions, hand-picked to land in the narrow band where the system produced correct answers. The other 97 questions — the ones real users would ask — hit hallucinations, timeouts, wrong tables, and a spectacular failure where the agent confidently reported $2.3M in quarterly revenue from a staging database with test data.
I've seen this happen to us, to startups we advise, to companies that raised millions on a demo. The pattern is always the same: build something that looks like it works, show it to people who don't know the edge cases, and confuse "the API returned a plausible response" with "we have a product."
There's a chasm between "call an API and show the response" and "build a reliable system that handles real-world messiness." This post is about what's in that chasm. Here's what we learned building through it.
The GPT wrapper trap
A GPT wrapper is an application where the core logic is: take user input, send it to a language model API, display the response. Maybe you format the prompt. Maybe you add some system instructions. Maybe you slap a nice UI on top. But the heavy lifting is "call OpenAI, hope for the best."
This works in demos for a very specific reason: demos are controlled environments.
The person giving the demo picks the questions. The dataset is small and clean. There are no edge cases because nobody's trying to break it. There are no consequences when something goes wrong because it's a demo. And the audience is evaluating "did it produce a reasonable-looking answer?" not "is this answer correct and can I bet my business on it?"
Here's why it breaks in production:
Users ask unanticipated questions. Your demo covered "what was revenue last quarter?" But in production, someone asks "what was revenue last quarter excluding the Acme deal that got restructured in January?" The wrapper has no idea what to do with that.
Context is too large for a single prompt. Your demo database had 3 tables. Production has 47 tables, 12 views, and a schema that evolved over 4 years with column names like amt_2 and legacy_status_old. Dumping all of that into a prompt produces garbage.
The model hallucinates with no catch. In the demo, every answer happened to be right. In production, the model confidently joins the wrong tables, invents column names, and returns numbers that look plausible but are off by 10x. There's no validation layer. No sanity check. Just raw model output piped to the user.
Error handling is "try again." API times out? Show an error. Database connection drops? Show an error. Model returns malformed JSON? Crash. There's no retry logic, no fallback, no graceful degradation.
No state. Every question starts from scratch. User asks "what about last month?" and the system has no idea what "what" refers to. The conversation history is either missing or stuffed wholesale into the next API call until the context window overflows.
No audit trail. When the CFO asks "where did this number come from?", you can't answer. The prompt is gone. The intermediate reasoning is gone. All you have is the final output.
The GPT wrapper is the "hello world" of AI products. It proves the API works. It does not prove you have a product.
Context engineering — the real skill
The most important skill in building AI products isn't picking the right model. It's deciding what information goes into the context window and how it's structured.
This might sound obvious. It isn't. I've talked to teams that spent months evaluating GPT-4 vs. Claude vs. Gemini while paying almost no attention to what they were putting in the prompt. They were optimizing the engine while filling the gas tank with sand.
The context window problem
Even with 128K+ token windows, more context does not mean better answers. It usually means worse answers. The model has to find the relevant signal in a sea of noise, and it's not great at that. Research from Liu et al. ("Lost in the Middle," 2023) showed that models perform significantly worse on information buried in the middle of long contexts compared to information near the beginning or end.
Retrieval isn't optional. You need to dynamically select relevant context per query. And the way you select and structure that context is the difference between a right answer and a hallucination.
What good context engineering looks like
Schema awareness at runtime. The agent needs to know your database structure, but not by hardcoding it into a prompt. Schemas change. Tables get added. Columns get renamed. We pass schema information dynamically, filtered to what's relevant for the current query:
// Naive: dump everything into the prompt
const allSchemas = await db.getFullSchema(); // 47 tables, 400+ columns
// Result: model picks wrong tables, invents joins, hallucinates columns
// Better: select relevant schemas based on the question
const relevantTables = await schemaRouter.match(userQuery);
// "revenue last quarter" → ["transactions", "subscriptions", "plans"]
const schemas = await db.getSchemas(relevantTables);
// Result: model sees 3 tables, 22 columns, gets it rightDynamic context selection. A revenue question needs Stripe schema and recent transaction data. A support question needs ticket data and customer context. A churn question needs usage metrics, billing history, and support interactions. Different questions, different context. If you're stuffing the same blob into every prompt, you're doing it wrong.
Context ranking. When multiple sources are relevant, you need to prioritize. If someone asks about a specific customer's billing, the customer's actual invoice records should rank higher than general billing schema documentation. Specificity wins.
Token budgeting. This is the one nobody talks about at conferences. You have a finite context window, and you need to allocate it deliberately:
System prompt: ~800 tokens
Schema context: ~2,000 tokens
Retrieved data: ~3,000 tokens
Conversation history: ~1,500 tokens
Response space: ~2,000 tokens
Safety margin: ~700 tokens
─────────────────────────────────
Total budget: ~10,000 tokensThose numbers are illustrative, but the discipline is real. If your conversation history grows unbounded, it eventually crowds out the schema context, and the model starts hallucinating column names because it can't see the schema anymore.
The same question, two different outcomes
Here's what this looks like in practice. Same question: "What's our MRR growth rate this quarter?"
Naive context (dump everything): The model receives all 47 table schemas, the last 20 conversation messages, a 3-page system prompt, and no actual transaction data. It generates a SQL query against a table called monthly_revenue that doesn't exist. It looked plausible. The table name was a hallucination.
Engineered context: The schema router identifies subscriptions and transactions as relevant. The context assembler pulls the schemas for just those two tables, includes a note that MRR is calculated from active subscriptions (not the transactions table), and trims conversation history to the last 3 relevant exchanges. The model writes a correct query against the right tables.
Same model. Same question. The only difference was what went into the context window.
We spent more time on context engineering at Zosma than on any other single component. It's not glamorous work. But it's the work that determines whether your agent gives right answers or plausible-sounding wrong ones.
Tool use in practice
An agent that can only generate text is a chatbot with extra steps. The thing that makes an agent an agent is that it can take actions: query a database, call an API, read a file, execute code.
Sounds simple. It isn't. Here are the challenges nobody mentions in the blog posts about tool use.
Authentication is a mess
Each data source has its own auth model. Stripe uses API keys. PostgreSQL uses connection strings with user/password or certificate auth. HubSpot uses OAuth 2.0 with refresh tokens that expire. Google Analytics uses service accounts with JSON key files. Slack uses bot tokens with granular scopes.
Your agent needs to manage all of these securely. Store credentials encrypted. Rotate tokens before they expire. Handle OAuth refresh flows without dropping a user's request. And never, ever log a credential to the audit trail. This is plumbing work, and it's a surprising amount of code.
Error handling for tool calls
In the real world, things break:
- Database query times out because someone's running a migration
- Stripe API returns a 429 (rate limit) because you're pulling 10,000 invoices
- HubSpot returns a 500 because HubSpot
- The CRM OAuth token expired 3 minutes ago
Your agent needs to handle each of these gracefully. Retry with backoff. Fall back to cached data if appropriate. Tell the user "I couldn't reach Stripe right now, here's what I have from 2 hours ago" instead of crashing. A GPT wrapper that hits an API error just dies. A production agent recovers.
Result interpretation
A raw Stripe invoice object has 40+ fields. The agent needs to know which ones matter for the user's question. If they asked "how much does Acme owe us?", the answer is in amount_due and status, not billing_reason or subscription_proration_date. This sounds trivial, but multiply it across dozens of tool responses per session and it becomes a real engineering problem.
Tool selection
"Revenue last quarter" → Stripe. "Active users" → your database. "Pipeline value" → CRM. "Customer satisfaction" → support tool. Some questions need multiple tools. "Revenue from customers who filed support tickets last month" needs Stripe AND your support system, joined on customer ID.
In OpenZosma, tool use is first-class. Every tool has a schema, input validation, error handling, and output normalization:
{
name: "query_stripe_revenue",
description: "Query Stripe for revenue data within a date range",
parameters: {
startDate: { type: "string", format: "date", required: true },
endDate: { type: "string", format: "date", required: true },
granularity: { type: "string", enum: ["day", "week", "month"] }
},
validate: (params) => {
if (new Date(params.startDate) > new Date(params.endDate)) {
throw new ValidationError("startDate must be before endDate");
}
},
execute: async (params) => {
const result = await stripe.balanceTransactions.list({
created: {
gte: toUnixTimestamp(params.startDate),
lte: toUnixTimestamp(params.endDate),
},
type: "charge",
limit: 100,
});
return normalizeRevenueData(result, params.granularity);
},
onError: (err) => {
if (err.statusCode === 429) return { retry: true, backoff: 2000 };
if (err.statusCode >= 500) return { fallback: "cache" };
throw err;
}
}That's not pseudocode. That's close to what our tool definitions actually look like. Every tool knows how to validate its inputs, call the external service, normalize the response, and handle failures. The model just picks the tool and provides the parameters.
Sandboxing — because agents take actions
Here's the thing about agents that most wrapper builders don't think about: agents take actions. They write SQL queries. They call APIs. They can modify data.
That SQL query the agent just generated? It could be a SELECT. It could also be a DROP TABLE. The Stripe API call? It could list invoices. It could also issue refunds. If you're running agent-generated code without isolation, you're one bad prompt away from a very bad day.
Per-user sandboxing
Every user session runs in isolation. User A can't access User B's data. Not just at the application level — actual execution isolation. User A's agent runs in a separate sandbox from User B's agent. If User A asks a question that somehow generates malicious code, the blast radius is contained to User A's sandbox. User B's session is unaffected.
This matters more than people realize. Multi-tenant AI systems where all users share an execution environment are one prompt injection away from a data breach.
Read vs. write permissions
Most BI queries are reads. But some legitimate agent actions need writes: updating a record, sending a notification, creating a report. The permission model needs to be granular:
- Always allowed: Read invoices, query revenue, list customers
- Requires confirmation: Send email to customer, create a report, update a record
- Never allowed: Delete data, modify permissions, access other tenants
This isn't a suggestion. It's a requirement. Without granular permissions, you're giving an AI unrestricted access to your production systems and trusting that it'll never make a mistake. It will.
Rate limiting and resource bounds
An agent in a reasoning loop can generate a lot of queries. We've seen cases where a complex question triggers 15+ database queries as the agent iterates toward an answer. Without limits, a single user's question could hammer your database and degrade performance for everyone.
Token budgets. Query limits per session. Execution timeouts. Maximum result set sizes. All of these are necessary. None of them are glamorous. All of them are the difference between "works in production" and "brought down the database on a Tuesday."
OpenZosma uses OpenShell for per-user sandboxed execution. Each session gets its own isolated environment with defined resource bounds. If it crashes or runs wild, the blast radius is contained. We didn't build this because it was fun. We built it because the first time an agent ran a SELECT * on a 200GB table with no LIMIT clause, we learned our lesson.
State management — the unsexy hard problem
Chat is stateful. Users expect the agent to remember context. "What about last month?" makes no sense without knowing what "what" refers to. "Break that down by region" requires knowing what "that" is.
Most GPT wrappers handle state by dumping the entire conversation into the next API call. Works for 5 messages. Breaks at 50. Unusable at 500. And for scheduled tasks — "generate this report every Monday" — there's no conversation to dump at all.
The challenges
Conversation memory. You can't keep everything forever. A user who's had 200 exchanges about 15 different topics has a conversation history that exceeds any context window. You need to decide what to keep, what to summarize, and what to let go. Get this wrong and the agent "forgets" important context. Get it wrong the other way and the context window is so full of stale history that current queries suffer.
Session continuity. User asks a question at 3pm, closes their laptop, and comes back at 9am the next day. "Can you show me that revenue breakdown again?" The agent needs to know what "that" refers to across a 16-hour gap. This means persistent session storage, not just in-memory conversation arrays.
Long-running tasks. "Send me a revenue summary every Monday morning" isn't a chat message. It's a scheduled task that spans sessions, requires its own execution context, and needs to handle the case where the data source is temporarily unavailable at 6am on a Monday.
Result caching. Three people on the same team ask "what was revenue last quarter?" within an hour. You don't want three identical Stripe API calls. But you also don't want to serve stale data from 6 hours ago. Cache invalidation in AI systems is cache invalidation everywhere else but worse, because the user doesn't know they're getting cached data unless you tell them.
Our approach
- Conversation summaries that compress without losing semantic meaning. After N exchanges, the oldest messages get summarized into a compact representation that preserves what was discussed and decided, without consuming the full token count of the original messages.
- Persistent session storage that survives disconnections. Your session state is stored server-side and rehydrated when you reconnect. The agent picks up where it left off.
- Task queues for scheduled and long-running operations. Monday morning reports run through a separate execution pipeline that doesn't depend on an active chat session.
- Intelligent caching with TTL based on data freshness requirements. Revenue data gets a 1-hour TTL. User count gets a 15-minute TTL. The agent always tells you when the data was last fetched: "Source: Stripe, queried at 9:14am" vs. "Source: Stripe, cached from 8:02am."
None of this is novel computer science. It's all well-understood engineering. But most AI products skip it because it's not the exciting part. And then they wonder why users complain that the agent "forgot what we were talking about."
What a real architecture looks like
Here's a simplified version of how a request flows through OpenZosma:
- User question comes in: "What was our MRR growth rate this quarter?"
- Context assembly: Schema router identifies relevant tables. Context assembler pulls schemas, relevant data samples, and trimmed conversation history. Token budget enforced.
- Tool selection: The model identifies that this requires querying the subscriptions table and potentially the transactions table. It picks the appropriate tools.
- Sandboxed execution: The query runs in the user's isolated sandbox. Read-only permissions. 30-second timeout. Result set capped at 10,000 rows.
- Result synthesis: Raw query results are normalized, interpreted, and formatted into a natural language response with source attribution.
- Response with sources: "MRR grew 8.3% this quarter, from $43,200 in January to $46,800 in March. Source: subscriptions table, queried at 2:14pm."
- Audit log: Every step recorded. The context that was assembled. The tool that was selected. The query that ran. The raw results. The final response. Fully traceable.
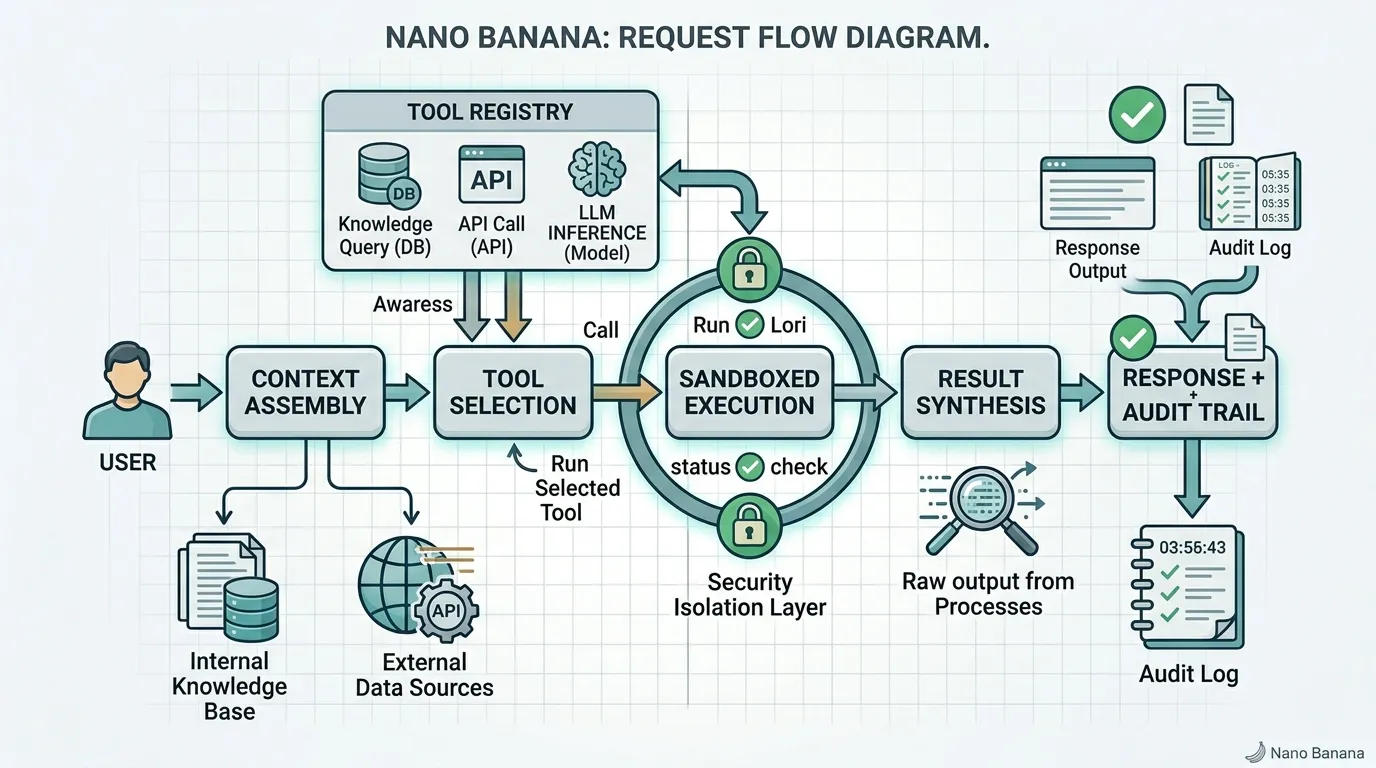
The model is one component. Around it: context engine, tool registry, execution sandbox, state manager, audit logger. That's the real product. The model is the CPU. Everything else is the computer.
OpenZosma's stack
- Hono for the API layer — lightweight, TypeScript-native, fast
- MCP (Model Context Protocol) for tool integration — universal protocol with 10,000+ public servers and 97M+ monthly SDK downloads
- A2A (Agent-to-Agent Protocol) for inter-agent communication — when a question needs multiple specialized agents to collaborate
- OpenShell for sandboxed execution — per-user isolation with defined resource bounds
- Structured audit logging — every decision, query, and result traceable end to end
We open-sourced all of this under Apache 2.0. Not because we're generous — because we think agent infrastructure should be inspectable, forkable, and improvable by the community. If you're going to trust an AI system with your business data, you should be able to read the code that handles it. "Trust us, it's secure" is not a security model.
The hard parts are the product
If you're building an AI product and it works in the demo but breaks in production, the problem probably isn't the model. It's everything around the model.
The model is the easy part. You call an API. It returns text. Done. The hard parts:
- Context engineering — deciding what the model sees and how it's structured
- Tool reliability — authentication, error handling, result normalization across a dozen different APIs
- Sandboxing — making sure agent-generated code can't cause damage
- State management — maintaining coherent conversations across time and sessions
- Observability — knowing what happened, why, and being able to explain it to a user or an auditor
Every AI startup that fails in 2026 will fail not because the models weren't good enough, but because the engineering around the models wasn't good enough. GPT-4 was already good enough in 2023. Claude has been good enough. Gemini has been good enough. The bottleneck was never intelligence. It was plumbing.
If you want the non-technical version of what this means for your business — what an agentic harness is and why it matters — we wrote that up in What Is an Agentic Harness?. And we'll go deeper on why we open-sourced OpenZosma and what it actually does in an upcoming post.
But the core point is simple: if your "AI product" is an API call wrapped in a UI, you don't have a product. You have a demo. And the distance between the two is where most teams get lost.
The API call is the easy part. Everything around it is the product.